Open Linked Data, DBpedia, Serendipity, and the Future of Web – Interview with Kingsley Idehen
 Follow
FollowBeing a Semantic Web, Open Linked Data, Open Source enthusiast, and at some point the contributor to the AP for the FOAF and other metadata standards, recently I had an opportunity to talk with Kingsley Idehen on his current projects, views on the use of the Web technologies, Open Linked Data, WebID, serendipity, and certain aspects of the Internet that influence our everyday lives.
") Kingsley Idehen is the Founder & CEO of OpenLink Software. He is a recognized technology enthusiast and expert in areas such as: Data Connectivity middleware, Linked Data, Data Integration, and Data Management. He is also a founding member of DBpedia project via OpenLink Software. Kingsley’s background is quite varied: he had planned to become a scientist in the genetic engineering realm but ended up being more fascinated by the power Information Technology and its potential to reshape mankind. From science, accounting, and programming, he followed his scientific instincts to architect OpenLinkVirtuoso, a powerful and innovative open source virtual database for SQL, XML, and Web services. The Virtuoso History page tells the whole story about Kingsley’s vision and accomplishments. You can follow him on Twitter and read his Google+ posts.
Kingsley Idehen is the Founder & CEO of OpenLink Software. He is a recognized technology enthusiast and expert in areas such as: Data Connectivity middleware, Linked Data, Data Integration, and Data Management. He is also a founding member of DBpedia project via OpenLink Software. Kingsley’s background is quite varied: he had planned to become a scientist in the genetic engineering realm but ended up being more fascinated by the power Information Technology and its potential to reshape mankind. From science, accounting, and programming, he followed his scientific instincts to architect OpenLinkVirtuoso, a powerful and innovative open source virtual database for SQL, XML, and Web services. The Virtuoso History page tells the whole story about Kingsley’s vision and accomplishments. You can follow him on Twitter and read his Google+ posts.
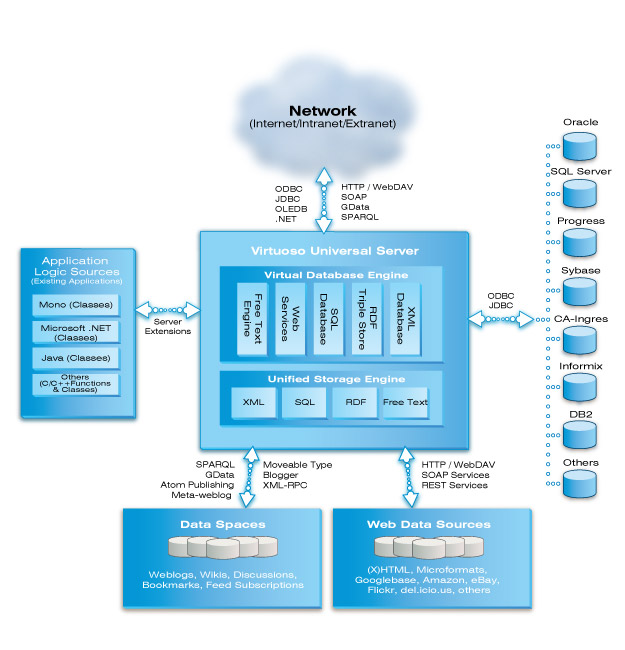
Would you explain to our readers a bit about the OpenLink Software, for those in the Web technology who may not be familiar with it? Can you give us a story about the inception, history, work and achievements of the OpenLink Software?
OpenLink Software develops, deploys, and supports bleeding edge technology covering the following realms:
1. Relational Database Connectivity Middleware — ODBC, JDBC, ADO.NET, OLE-DB, and XMLA Drivers/Providers
2. Disparate Data Virtualization
3. Personal & Enterprise Collaboration
4. Relational Tables (RDBMS) and Relational Property Graph (Graph DB) based Database Management Systems
5. Federated Identity Management.
I founded OpenLink in 1992 with open database connectivity middleware supporting all major RDBMS products as our focus. By 1998 we evolved our vision to include RDBMS virtualization, and by 2000 we decided that the Semantic Web technology stack provided all the critical standards that would enable us extend data virtualization to include other data sources and formats beyond the RDBMS.
OpenLink was initially associated with dispelling the performance myth that undermined the early promotion of the Open Database Connectivity (ODBC) standard from Microsoft. In the Semantic Web and Linked Data realms our Virtuoso hybrid data server underlies critical parts of the Linked Open Data cloud (starting with DBpedia which lies at the core) as well as offering the largest publicly accessible Linked Data space on the planet, against which anything (human or machine) can perform ad-hoc queries that drive lookups while also aiding the emergence of other Linked Data Spaces on the LOD cloud.
Naturally, our technologies are used extensively across enterprises worldwide due to performance, scalability, and security that underlies every item in our product portfolio.
Is there any existing tools and methodologies developed by either you or your team in the OpenLink Software or others that you would like to mention?
* High-Performance ODBC Drivers for all the major RDBMS databases
* ODBC Drivers for the World Wide Web — yes, the World Wide Web of Linked Data (or LOD cloud) is exploitable and accessible to any ODBC, JDBC, ADO.NET, or OLE-DB compliant application
* Virtuoso — high-performance and massively scalable hybrid DBMS (relational tables and property graphs).
* Linked Data Middleware — that transform output from a plethora of Web 2.0 and SOA services into structured Linked Data
* URIBurner — a public instance of the middleware mentioned above that enables anyone transform existing data into Linked Data
* OpenLink Data Spaces — platform for enterprise and personal data spaces that includes in-built Federated Identity and sophisticated Linked Data functionality
* DBpedia — Linked Open Data Cloud nexus that runs on Virtuoso (re. Linked Data Deployment and Data Management).
Some useful links and downloads: ODBC Drivers for the World Wide Web, Virtuoso Commercial Edition, Virtuoso Open Source Edition, Linked Data Middleware, URIBurner, OpenLink Data Spaces, and DBpedia.
Do you collaborate with similar organisations/institutions worldwide in the field of the Open Linked Data? Would you tell us more about your involvement within the DBpedia project?
Yes, as demonstrated by DBpedia (Frei University and University of Leipzig), Sindice (DERI), and Bio2RDF(Carleton University and others).
Virtuoso is the Linked Data Publishing and Database Management system behind DBpedia. Net effect of Virtuoso is you have a massive collection of Linked Data derived from Wikipedia that’s available to the entire public. This instance enables you browser through pages that describe entities while also delivering ad-hoc query functionality via a Web Service that supports the SPARQL query language, results serialization formats, and HTTP based wire protocol.
In addition to providing the live instance, we also provide quality assurance, support and maintenance. Publishing and maintaining DBpedia is a challenge, and we even offer packages that enable others instantiate personal or service specific instances via Amazon EC2 AMIs (virtual machines).
DBpedia is basically germination of the seed planted by the Linked Data meme published by TimBL circa. 2005. In turn, DBpedia enabled the emergence of the massive Linked Data Cloud that exists today.
In his recent keynote, at the WWW2012, Tim Berners-Lee talked about the importance of the openness and urged for governments to embrace the movement of open data. Following that, you showed me how one can successfully kill spam using the WebID protocol as a Web-scale verifiable identity mechanism. Thus, for those who are not familiar with WebID – beside allowing to identify self online and exchange the WebID with other people and social web services – are there some other uses aimed at solving real problems?
Here are the fundamental problems solved by unadulterated open data connectivity:
1. generating capital from high quality government data via open data initiatives the leverage Linked Data principles — this is better than dysfunctional financial engineering that’s plunged the world into an economic fragility
2. big data and small data virtualization that simplifies the process of discovering and sharing insights for individuals and enterprises alike
3. achieving the goals above without compromising privacy and security.
There’s nothing more useful than 1-3 and there’s no technology to date that’s achieved that without some kind of platform specificity that ultimately becomes a dysfunctional silo. This is where the Web is unique, as its impact on mankind has already demonstrated with aplomb.
I always ask people who are in the ICTs (Information-Communication Technologies): do you think that Web is one big serendipity machine from the computing and the scientific point of view?
It is. See: SDQ (Serendipitous Discovery Quotient) and The Future of SEO? Or an Abstract Concept? – another SDQ article.
As the links to structured data increase on the Web, its density increases, which ultimately means that you require fewer and fewer link hops to find whatever you seek, with precision.
For instance, you can Find all Blog Posts about a Subject Matter Topic based on the attributes of the topic since the Post, Topic, and their Connection are all denoted (named) using hyperlinks (de-referencable) URIs. These URIs resolve to content in the form of fine-grained links taking the form: entity-attribute-value or subject-predicate-object. See my presentation that covers the basics of structured of data.
Do you think that Web apps and software architects are killing the serendipity moment with their search algorithms, mechanical turks and other mechanisms?
No, the worst that can happen is artificial protraction of a journey to an inevitable destination i.e., the Web as mankind’s distributed database and serendipity machine.
What are you currently working on? What’s your current projects and research about? What can we expect from the OpenLink Software in the upcoming period?
Addressing the Read-Write dimension of the Web, hence the recent emphasis on WebID and the WebID authentication protocol. Verifiable Identity is a critical piece of the Web that hasn’t manifested coherently until the emergence of the WebID and Read-Write Web community groups from the W3C.
All our products are WebID enabled, so our current focus is getting the world to understand why federated identity matters by product offerings that address:
1. Personal Data Spaces or Data Lockers — how users take full control of their identity, profiles, data, and privacy
2. Data Wikis – basically reapplying the Wiki Content pattern to Linked Data such that crowdsourcing and social networking add new virtuous dimensions to Linked Data product and quality.
What is taking up the most my time these days is finalizing a boat load of new product releases that increasingly simplify the power inherent in our products and the infrastructure provided by the World Wide Web. Also, OpenLink Software is finalizing new editions of Virtuoso, OpenLink Data Spaces, and its suite of ODBC and JDBC compliant data access drivers which support all major DBMS engines.
Thank you Kingsley for taking your time to talk with me!
Radovanovic D (2012-07-30 01:26:39). Open Linked Data, DBpedia, Serendipity, and the Future of Web – Interview with Kingsley Idehen. Australian Science. Retrieved: May 06, 2026, from http://ozscience.com/interviews/open-linked-data-dbpedia-serendipity-and-the-future-of-web-interview-with-kingsley-idehen/
1 thought on “Open Linked Data, DBpedia, Serendipity, and the Future of Web – Interview with Kingsley Idehen”
Comments are closed.