Reddit: Google’s Semantic Data-Mining Opportunity

 Follow
FollowLook at this perfectly looped image sequence. It’s link building, chain making, Futurama, factory… it’s satisfying, and hypnotic. Google, however, won’t be able to link these concepts well enough unless it’s fed structured semantic data. They must find creative ways to correlate “strings” and understand “things” as webmasters don’t always have a habit of structuring their data, just like they don’t always use rel=”nofollow” or write clean code.

This is where hierarchical discussion threads can help. For the sake of practical understanding of difficulties associated with structured comments, I selected a semantically challenging Reddit thread and examined the topical hierarchy of top-level comments and how they iterate into related sub-topics. Here are my notes:
Semantic Hierarchy Breakdown
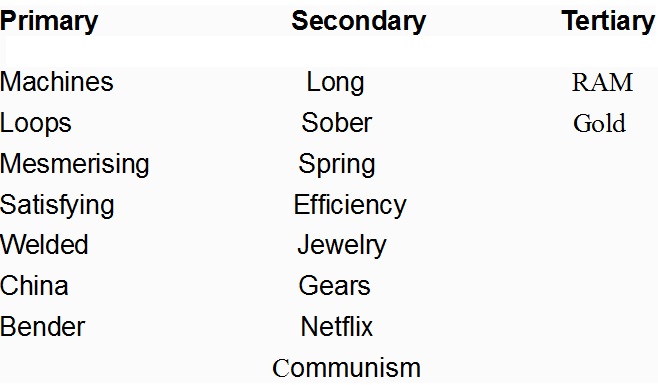
Primary Level: Related Terms
The image describes a looping, repetitive, bending process by a chain making machine. It symbolises perfection and has a satisfying / narcotic / mesmerising effect on the viewer. The highlighted terms are semantically related in the context of this image and potentially in other situations. We also learn that word “chain” is often misspelled as “china” and vice versa which could potentially serve in Google suggest.
Secondary Level: Semantic Pairs
The comments allow for discovery of visually similar processes and objects such as jewelry chains and springs. A search engine can also start linking semantically connected pairs such as:
Bender – Futurama
Loop – Long
Machine – Efficiency
Tertiary Level: Semantic Branches
Tertiary level shows signs of severe topical dilution, but still shows valuable semantic tree harvesting potential. Word machine is linked with efficiency which is linked with RAM.
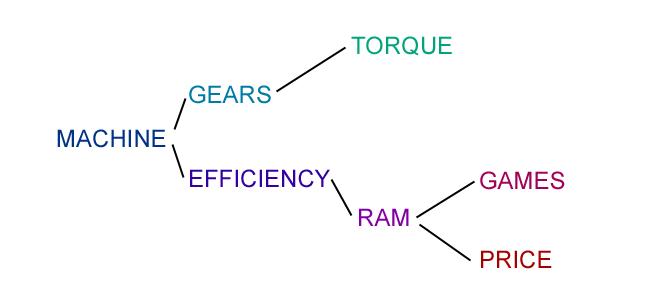
SemRank
SemRank (Semantic PageRank) is a concept I use to describe distribution of topical relevance and dampening within diverging semantic hierarchies including comment threads and other semantic structures on the web. Similarly to random surfer model, complex semantic trees may be applicable for PageRank-like treatment where every node in a semantic tree chain is less likely to be strongly related to the original discussion.
Unlike PageRank however, semantic dampening factor represents a topical shift and loss of importance in respect to the original concept and does not represent a general loss of importance in the overall semantic graph. This means that within a semantic tree, a comment on the fifth level of the discussion hierarchy can have as much value as a top level comment.
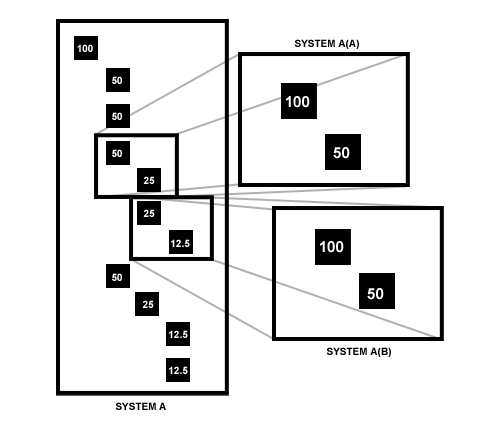
The figure above illustrates topical dampening and iteration where each hierarchy level carries a 50% chance of topic slide. Observe how values change when SYSTEM A(A) and SYSTEM A(B) are observed in their own frame of reference. A node with a semantic connectivity score of 12.5 in respect to the main topic also carries a score of 50 in respect to it’s direct superior node. SemRank is therefore a relative value which depends exclusively on the distance from the selected reference node.
In order to ascertain the overall importance of a comment, an algorithm designed to work with discussion thread hierarchy can also factor in comment’s downtree (the entire semantic structure stemming from the original comment). Downtree voting system would obey the SemRank principle, allowing for comments closer to the primary node of the down-tree to contribute with a greater amount of semantic juice.
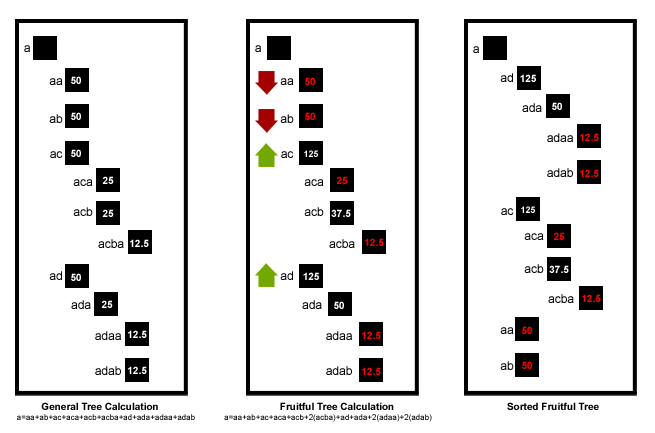
Importance of an item can be expressed quantitatively by (a) the sum of all its’ downtree nodes or, (b) by repeating the same process while rewarding fruitful branches with a cumulative score (see Fruitful Tree Calculation). The semantic tree can then be sorted by node score, surfacing richer discussion sub-topics.
Reddit algorithm already orders comments in a similar fashion using an explicit voting system where users can up-vote or down-vote comments. User-generated quality signals can be effective on a qualitative level, but don’t always reflect semantic connection to the original topic.
I propose use of a hybrid method for voting-enabled communities in order to balance available metrics in a single semantic quality score.
Google’s algorithm is already equipped with mechanisms to process semantic graphs. Whether they can find their way around structured discussion threads and harvest valuable semantic data is uncertain.
Academic Research
A paper called “An Exploration of Discussion Threads in Social News Sites: A Case Study of the Reddit Community” by Tim Weninger, Xihao Avi Zhu and Jiawei Han examines topical hierarchy of comment threads on Reddit in order to enhance web search. The paper proposes use of comment threads to annotate linked content.
Here are some of their findings:
- Hierarchical comment threads consist of top level comments that start a subtopic.
- Top level comments, especially those which receive a large number of replies, are usually created during the early stages of the post’s life cycle.
- From among the early, top-level comments/subtopics further sub-subtopics are created as a natural part of online discourse.
- Hierarchical comment threads on Reddit represent a topical hierarchy.
Update:
One of our readers, Miloš Milosavljević made an interesting point questioning how best to handle/exclude trolling comments. Trolling can be on-topic and as such a valid source of semantic data, but it can also act as a topical cul-de-sac while still attracting a significant amount of replies (as an emotional response from the community). This could potentially inflate the semantic score of the troll’s comment. User-based voting system should act as a protection/moderation layer against such events.
Related paper: “Filtering Trolling Comments through Collective Classification“, Jorge de-la-Pe˜na-Sordo, Igor Santos, Iker Pastor-L´opez, and Pablo G. Bringas