What is Big Data, and why it matters?

 Follow
FollowIn the past few years you probably read everywhere about the “new big thing ” – the big data promise, opportunities, challenges, etc. What is actually big data? A new concept, a social media buzzword, or maybe something else? The first mention of “big data” term happened in 1997 in the Application-Controlled Demand Paging for Out-of-Core Visualization – NASA (Source: http://dl.acm.org/citation.cfm?id=267068). The term is believed to have originated with web search companies who had to query very large distributed aggregations of unstructured data.
Big Data refers to technology (tools and processes) and large amounts of data that is difficult to store, manage, analyse, share, and visualise with the traditional database software tools. From the semantic perspective, big data isn’t new concept at all: every time we generate data, we also generate metadata, “data about data”, along with the data protocols. From technological point of view, big data is just a buzzword, aiming to describe a large volume of both structured and unstructured data. Those massive data sets are difficult to process therefore they require using traditional database and software techniques.

Technologically, it is a continuation of what people were doing with big data sets before. Nowadays, we have much more data and fancier hardware and software, but that is not the big new thing as well.
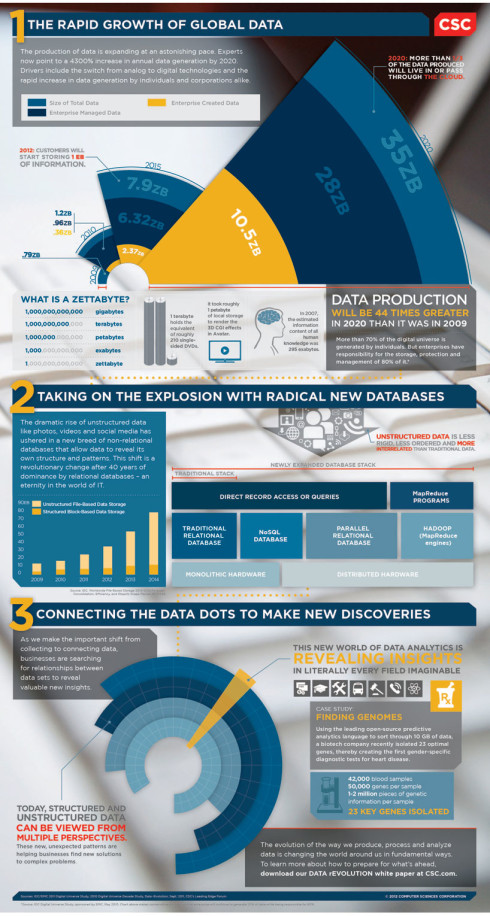
The big new thing is that data is too massive or it moves too fast or it exceeds current processing capacity, as back in 2001, industry analyst Doug Laney indicated the big data as the three Vs: volume (large amount of data), velocity (needs to be analysed quickly), and variety (different types of structured and unstructured data). Volume – referred to factors that contribute to the increase in data volume, including the unstructured data streaming in from social media sites. An example of big data can be petabytes (1,024 terabytes) or exabytes (1,024 petabytes) of unstructured data that is often incomplete and inaccessible. Issues regarding the volume include how to determine the relevance within large data sets and how to use the analytics because standard tools and procedures are not designed to search and analyse massive datasets. Velocity denotes that data is streaming in “at unprecedented speed and must be dealt with in a timely manner. RFID tags, sensors and smart metering are driving the need to deal with torrents of data in near-real time.” Variety implies that data is being generated in all types of formats. Structured, numeric data, unstructured textual documents, video, audio, email, social media data, and financial transactions. The real challenge for many organisations is to manage, merge and govern different varieties of data.
New thing is also that all the big data enables new business models. The data itself can be valuable, aside from the rest of business; not just because enterprises can use it to improve how they run project or business but because data enables them to make entire new businesses possible.
Big data analysis refers to discover patterns and other useful information within the data, that is important for both for the scientific research, and social engineering where social scientists will be able to predict the interactions of people the way physicists predict the interactions of objects, with the potential limitations.
Scientists, are also working with big data, for example, the NASA Center for Climate Simulation (NCCS) integrates millions of observations collected daily, analysing observations and performing climate-change simulations. The center has also turned to visualization technologies to help scientists see their research in detail. The Center helps administer Discover’s archive system, which stores about 32 petabytes of data.
“The Big Data problem is like finding a needle in a needle stack,” says Scott Wallace, CSC NCCS Support program manager. “Finding your needle in a pile of 32 trillion needles is not significantly harder than finding it in a pile of one trillion needles because they’re both effectively impossible, unless you build in a way to keep track of where each needle is located.”
And this presents exactly one of the big problems with “big data“, along with the fact that big data can work well as an adjunct to scientific inquiry but rarely succeeds as a wholesale replacement, the risk of too many correlations between two variables, or that big data is best when analysing things that are extremely common, but often falls short when analysing things that are less common, etc.
As in many areas of global activity, information and communication technologies have found its use in public sphere a long time ago. They are mostly used for searching the information and data, and accessing the existing databases and data sets over the Internet. Usage of electronic information resources depends on good search capabilities. Because of that the Semantic Web concepts can present more efficient solutions for finding and analysing information.
With all its successes and failures, it is left to see if the big data trends are going to transform the way how we live, work and think in the future, and at the same time it would be exited to see its promises for data analysis in the science and research development.
Infographic on Big data, resource.
References:
http://www.csc.com/cscworld/publications/81769/81773-supercomputing_the_climate_nasa_s_big_data_mission
http://www.webopedia.com/TERM/B/big_data.html
http://blogs.hbr.org/2014/03/google-flu-trends-failure-shows-good-data-big-data/
Image source.
1 thought on “What is Big Data, and why it matters?”
Comments are closed.