Interview: Henry Story, a Social Web architect and Polymath
 Follow
FollowHenry Story studied Analytic Philosophy at Kings College London, Computing at Imperial College, worked for AltaVista where he developed the BabelFish machine translation service, worked at Sun Microsystems on Blogging platforms and the development of the Social Web where he developed the decentralised identity and authentication protocol known as WebID, which is under standardisation at the W3C (World Wide Web Consortium). He contributed to the Atom syndication format at the IETF (The Internet Engineering Task Force), to the Linked Data Protocol at the W3C, and is currently writing an Open Source platform for co-operating systems in Scala based on all those standards.
Henry has been giving talks on the philosophy of the Social Web at the Sorbonne University, and various other places. We took a moment to have a conversation with Henry on very interesting topics – from the early years of the World Wide Web, first search engines, Semantic Web, metadata and ontologies, to the current initiatives within the Web Consortium (W3C), WebID Incubator group activities and its impact on the scientific research.

Welcome! Would you, please, tell our readers a little bit more about yourself? Where do you come from, both geographically and philosophically? What is your scientific background, and your professional scope?
Hi, thanks for inviting me over. My background is one that crosses frontiers: both geographic/national ones as well as disciplinary ones. I somehow found myself at the intersection of philosophy, logic, programming, web architecture, standards and social networks development and recently startup creation. Furthermore my work has been more and more about exactly this: how to help people co-operate across such disciplinary boundaries in a global open manner.
To help make sense of this tangle it helps to go back a little bit in time. My father is English and received his PhD in Washington DC, my mother is Austrian and a sculptor, and both lived in France where my father taught until recently political economy at the INSEAD Business school. That explains the geographical/national tangle.
INSEAD is also where I learnt computing on a DEC 2020 around 1980 as I was 13 or so. I wanted to ask the computer how to solve the Rubix cube. Of course I was told that it would not be that easy. I had to learn to communicate with the machine and learn how to ask the question. This lead me to learn the programming language Basic, and soon after that Pascal which was a revelation – no GOTO loops needing rewriting whenever a new line was added to the program – just procedures. So I wondered what could there be that was better. I discovered Lisp which made it easy to conceive of a program that could write itself, and from there the questions of Artificial Intelligence and so of philosophy started to open up.
I could see around 1984 the beginnings of the internet appear as I went to the Centre Mondial in Paris that had Lisp Machines available and connections to 4 different centres around the world.
But at the time computers were changing too quickly – I was stunned when I saw the 1984 Apple Macintosh in a shop window, and how it had left the terminal behind for just a graphical interface – so I decided to learn something which seemed more stable and took maths, physics and English literature for A levels (in the UK) and then later analytic philosophy at Kings College London, which was the philosophy that emerged out on the work by Frege and later Bertrand Russel of mathematical logic. I returned to computers to do a MSc at Imperial College later, where I learnt about Unix, Prolog, Agent Oriented Programming, Functional Programming, and Category Theory. At the time I was wondering how all this would come in useful. How would they tie up together? It turns out that in my work on building a distributed decentralised secure social web what I learnt in philosophy as well as what I learnt at Imperial College are all immensely relevant. Indeed in the last few years I have been giving talks on the philosophy of the Social Web at the Sorbonne, and various other venues that do just that.
At the time I did not know it. At Imperial College we had participated in the early stages of the Web. We were using Sun workstations, publishing web pages, and I even saw the birth of Java, the language that promised to allow one to write code that could run on every computer – a must for distributing programs on the World Wide Web. Its success was assured as it was released with Netscape Navigator in 1995. I learnt it, wrote a little Fractal Applet for my homework, put it on my web page, and flew to San Francisco to the first JavaOne conference. In the UK most job agencies had either not heard of the web, or had no access to it. But in California it was completely different. When I told a student at Berkeley about my Web page he asked me for the URL, had a look at it on the spot and suggested I go to the WestTech conference in San Jose. There were 400 tech companies there looking to employ young people – the biggest equivalent in the UK I had seen was a job fair with 40 companies. As I was about to leave a few days later I received a call from AltaVista the top search engine at the time which had indexed 50 million web pages (!) which was a lot at the time. The web was growing exponentially as every person who wrote a web page linked up to other web pages they found interesting hoping to receive perhaps a link back in return, and so make their page visible on the web. This turned every publisher into a web advocate. I went to the interview and got the job. Finally I was back in the US 28 years after I had left it as a child of 5.
This one is very interesting for those who remember the early days of World Wide Web and the first translation engines. In the 90’s you worked as a senior software engineer for AltaVista on the BabelFish machine translation service. What happened with BabelFish?
Yes, at AltaVista, Louis Monier one of the founders with Mike Burroughs, presented me with the project to adapt the Systran translation engines as a web service. Those translation machines had an old history. In the 1960s they were written in assembly code – the low level code machines understand – and had slowly been ported to C, a low level but more easily portable language which operating systems are written in. But they were not designed to be run on the biggest web service at the time, with potentially 100s of thousands or even millions of users.
As the translations were not always that good I played on this weakness by naming the machine babelfish.altavista.com, in reference to the character from the BBC Comedy Series «The Hitch Hikers Guide to the Galaxy»: a fish that when placed in a person’s ear could feed on brainwave energy and translate every known language in the universe. I pushed out a quick version, and it was immediately very successful. Then I spent a lot of time trying to write a more advanced version in Java, but the compilers at the time produced code that ran much too slowly. Finally around 1999 big speedups arrived making it competitive with C, and it was possible to launch the final version of the servers, and move up to a million or 2 translations a day.
AltaVista’s big advantage initially was Digital Equipment Corporation’s 64 bit machines, that were 10 years ahead of Intel, allowing massive and efficient indexes to be built. AltaVista started by fetching the initial pages of Yahoo a human built directory of interesting web pages, retrieving links to pages, then fetching those, and so on recursively. It would then index all the words it found allowing users to instantaneously find information on the web. Sadly AltaVista never was able to take full account of the links between the pages to help with the ranking. Google worked out how to use the information that each web page author published when he links a web page to another one, thereby voting for it in a sense. Using the collective intelligence of the World Wide Web, Google came to produce more and more relevant results, overtaking AltaVista in 2001 as the largest search destination in the World.
Furthermore AltaVista was constantly undermined by management changes. First it was bought by Compaq (which was later to be bought by HP), then it was sold to CMGI which popped in the dot com bust of 2001, was then bought by Yahoo, and finally Yahoo closed it recently. I left well before in 2000 to join a translation startup, then came back to Europe.
In the end these hand written translators were overrun by Google’s translators tuned by statistical algorithms working on massive amounts of published text available on the web or scanned from books.
Also, you’ve been working on the Semantic Web since 2004 at Sun Microsystems. Semantic Web explorations and practical implementations were so popular, what happened to Semantic Web?
Tim Berners-Lee the inventor of the Web, first spoke of the Semantic Web in 1994 at the first World Wide Web conference, as a way to enable the web to not just be a web of linked human readable pages, but also a web of linked data. As the web was a hyper-text system, so the semantic web could become a hyper-data publication platform allowing people to connect data across organisational and national boundaries.
The first RDF standards appeared in the period 1999-2001. Blogging, one of the first applications of RDF, was started at the end of the millennium, and growing at exponential speeds. Around 2004 I had some time for myself and decided to write a blog. I found that James Gosling – the father of Java – had written and Open Source blog editor called BlogEd. I used that, fixed some bugs in it, then adapted it with a local RDF store. As a result he offered me a job at Sun Microsystems which I gladly took.
Sun Microsystems was a great company that had produced in 1981 the first colour graphical work station running Unix, the internet operating system, based on open standards that had emerged from the break up of AT&T. In 2004 Sun was emerging from the dot com bust, and was facing strong competition from Linux, the open source Unix clone developed in a distributed manner by a world wide community of engineers, which powered Google’s servers since the beginning, and was making inroad everywhere. But Sun had produced some of the best technology around, created a huge Unix and Java community. The CEO Jonathan Schwartz in a bold move had decided to move all of Sun’s code Open Source to compete with Linux. He also allowed and even encouraged us to all blog online, so that we could present a human face of what was a research focused engineering company.
What did blogging add to the web? In short it allowed everyone to publish information and let others know through a syndication feed (RSS then Atom a.k.a RFC 4287, which I contributed to) to subscribe to their updates. This allowed increasing distribution of content publication, allowing everyone to get the latest updates from their preferred authors world wide without needing to wait for the search engines to index those pages, a process which could potentially take months to reach updates, as they had to crawl the whole web for content.
Another very interesting application of the semantic web was FOAF – the Friend of a Friend ontology, put together by Dan Brickley and Libby Miller, and that was evolving in a friendly open source manner through open online discussions. FOAF allowed one to publish one’s profile on one’s web server, and link one’s profile to that of one’s friends who also published it on their web server. So just as with blogging and the web, everybody could participate in a distributed social web.
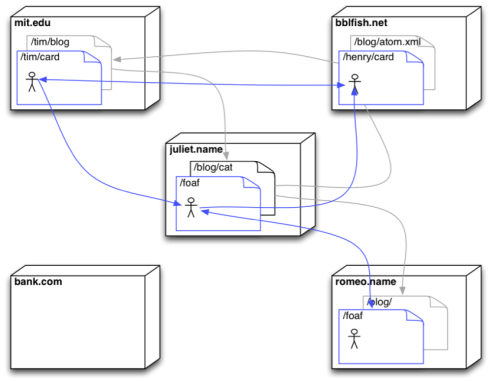
I wrote a distributed Address Book called Beatnik (take a look at this video), which made it easy to see how one could drag a FOAF profile from a web page onto the address book, and it would show you someone’s friends. You could then click on one of the friends to find their name, photo, contact information find out potentially where they currently were on the globe and follow explore their friends. All of this was totally distributed.
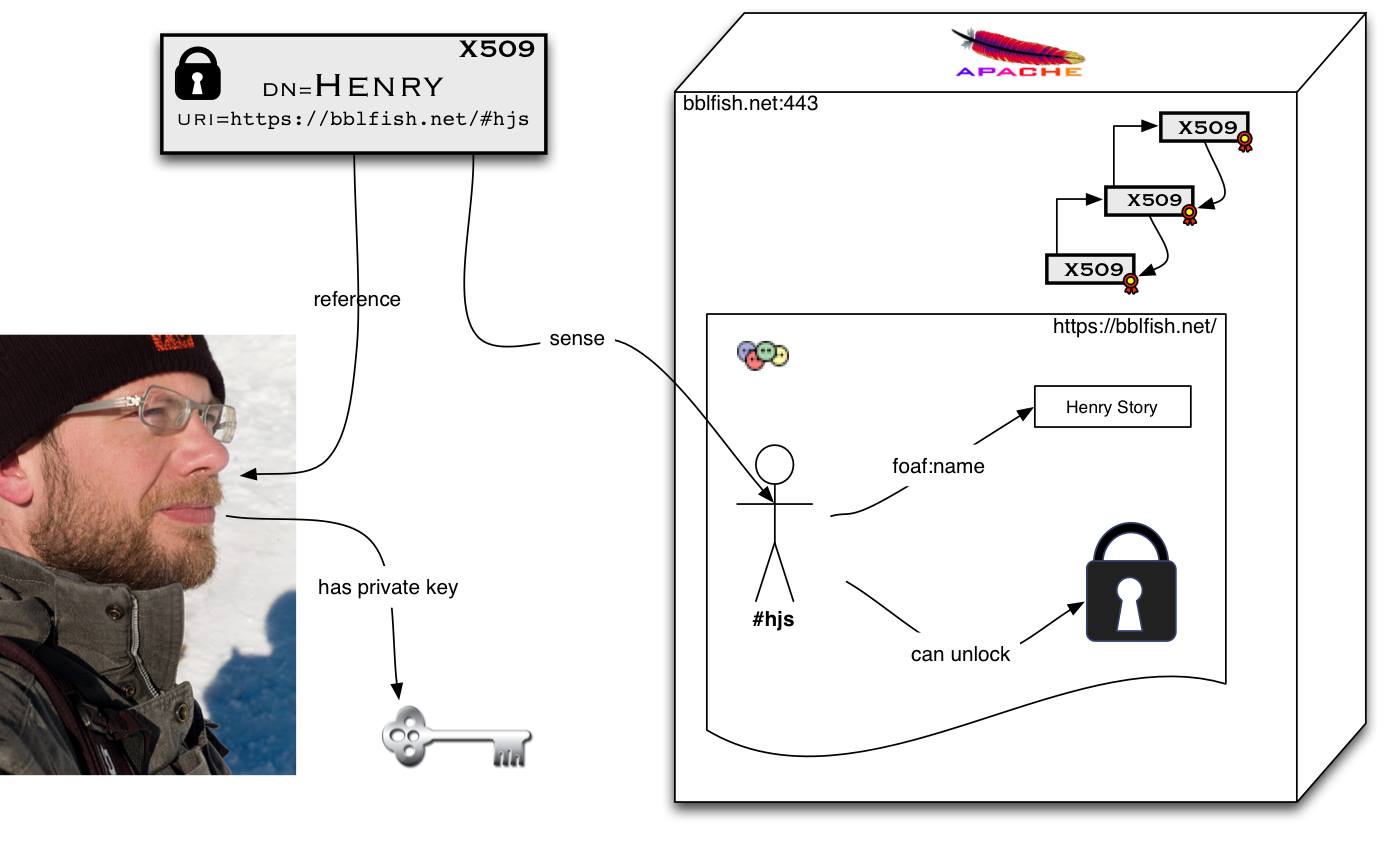
But at the time Facebook was starting to grow and people wanted privacy too. So the criticism I received was that this was all and good for publishing open distributed social networks but that one could not publish confidential information. To do that one needed a global identification system, so that one could connect to any web server one had never before gone to, authenticate with a global identifier, and be then given access to the resource if allowed. There was a standard for doing this that was gaining traction called OpenID, but OpenID was very slow requiring 7 http connections and required the user to type a URL in by hand. Having worked on large sites such as AltaVista this seemed to me very inefficient. I wondered if one could reduce those 7 connections down to one, while also removing the need for the user to even type anything. I asked around on the IETF mailing lists and by luck a few people answered, each one with a third of the solution. WebID was born. It allowed us to use TLS the security system used for commercial transactions on the web and built into every browser to enable authentication in one click to any web site securely using public key cryptography.
What we found was a beautiful hack to transform a system that was up to then used in a purely centralised manner, into a purely decentralised one. Usually client side certificates require one to have a certificate authority to sign the users information. This is expensive, cumbersome, not very flexible, and on the whole not even as trustworthy as it should be. WebID bypasses the certificate authority, and moves trust to the Social Web of published relations between people.
Would you explain to our readers a bit about the W3C WebID Incubator, for those in the science and technology who may not be familiar with the Incubator? Would you tell us more about your role within W3C WebID Incubator group?
We initially developed the protocol on an open mailing list called foaf-protocols. There we tested the ideas by listening to feedback from implementors from every walk of life. In a few years we had verified that this indeed could work correctly. We found the weaknesses in certain browsers and sent them bug reports. We slowly improved the description of the protocol. But as it became clear that it was workable and that we had nearly a dozen implementations we thought it would be time to go through a more formal process, and create a more formal looking document that would give people confidence in it. There the unofficial mailing list was no longer the correct venue.
Very early on I had sat down next to Tim Berners Lee to show him what we were calling at the time foaf+ssl protocol, and he immediately understood it even suggesting we use the name WebID. Tim had some of his students use it to work on developing a big picture of what this was leading to, which he called Socially Aware Cloud storage. So later when we asked him if we could have a space on the W3C to put together a standard for WebID. He approved completely. Nevertheless there are a lot of standards for identity competing for each other, and so this was a bit of a political mine field, and we settled for a low profile Incubator group status of which I am the chair.
Can you share with us some personal notes regarding the WebID Incubator, any challenges you faced along the way, and the outcome?
The beauty of WebID is its simplicity. So my role as the WebID Incubator group chair has been to try to keep it that way. I think small standards that do one thing well but that are designed to compose with other standards work best.
There was a lot of pressure by some folks who came in later to make things much more complex. Usually when one looks closer at those protocols, that complexity hides some centralising architectural presupposition, a number of security issues, or wishful thinking as to how things may work.
I did make a mistake initially by allowing myself to be argued into making WebID more general than it needed to be. It felt nice: it felt like we could have a standard that would encompass all identity systems. This is an easy mistake to make. It is one thing to design a protocol to make it easy to generalise, but it is another one to make it so general that it is difficult to implement. And initially what is needed is to keep it simple and clear so that implementors can follow a spec to write an implementation that works. Vendors often have an opposite need in that the more complexity they can manage the more they can distinguish themselves (they can tick more boxes on their software features set). This is where the rough consensus and working code mottos of the IETF and the W3C are key. A standard comes from having interoperable implementations written by different organisations that may not even know of each other’s existence. If nobody can implement the full standard, then it is not well specified enough.
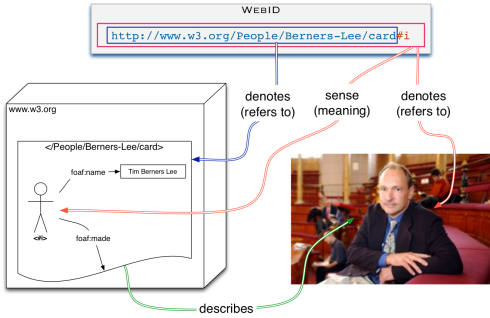
So under the good advice of Tim Berners-Lee a couple of years ago we decided to return back to the roots and create two specs, one that defines what a WebID is independently of authentication, and another that defines the WebID over TLS authentication. This means that we can get WebID to work with potentially other authentication mechanisms such as BrowserID (now called Mozilla Persona) that was a rising star a few years ago, but has run into trouble because it only had the promise of being decentralised sometime in the future, perhaps….
It now ties in very nicely with a number of emerging standards at the W3C such as:
•The Linked Data Protocol: is a standard to turn the web into a read/write web that has been Tim Berners-Lee’s ambition since the beginning. It takes the best of WebDAV and the Atom protocols that came before it, but simplifies them by integrating them in the semantic web. The Linked Data Protocol is being worked on by IBM, Oracle, Fujitsu, and a number of other companies. I represent Apache there, and probably had one of the first implementations of it, which I worked on with Alexandre Bertails of the W3C that was part of a proof of concept that led to the formation of the Working Group.
•Web Access Control: is a simple ontology and a pattern of linking a resource to it so that a client can (if allowed to) work out who has access to a resource and edit (using LDP) the access control rules which are themselves expressed in RDF. Authentication can be done with WebID over TLS, or other methods. This is still just a wiki page but it has a number of implementations.
Finally, what are you currently working on? Where do you see this leading to? How do you see this impacting the scientific research?
We have now the standards to build a platform for distributed creation, edition, and protection of any kind of information resource be it textual, image, video or data on the web, in way to allow the whole world to connect in ways only dreamed of until now. This of course opens up huge spaces of possibilities in every field.
We have built an implementation of this in Scala, a very interesting programming language that compiles to Java byte code or to JavaScript (with Scala-JS), available under an Apache licence on the read-write-web GitHub repository.
Scala is multi-paradigm programming language that mixes Object Oriented and Functional concepts, which in a world where Moore’s law can only continue progressing through parallelization is becoming essential. Consider that Sun’s latest CPU the T5 cpu contains 16 cores for a maximum of 128 threads per processor, for a total of 1024 on an 8 socket system. Old style Object Oriented programming with mutable objects requires complex systems of locks that are prone to dead-locks. Here mathematical programming which is what functional programming is all about is the cure. By working with non mutable data structures (objects) in a functional way that composes – hence the importance of Category Theory which is the study of such composability – one can guarantee that code can be parallelised.
With the advent of LDP+WAC+WEBID we now not only have paralellisation inside one CPU but now across organisations, where our servers potentially have to communicate constantly with 1000s of other servers. Here again the functional nature of Scala makes asynchronous programming vastly more efficient than traditional thread based programming, saving GB of RAM just to process connections on the internet.
With the advent of Scala-JS we can now envisage writing code that works inside the web browser as well as on the server. So we have now come to build a fully distributed agent platform with declarative and inferential semantics (RDF), speech/document acts (LDP) powered by functional programming languages, bringing together all the fields that I had studied twenty years ago at Imperial College in London.
This platform will allow researchers to connect up seamlessly, link up different data sets together, tie articles to the data sets they were based on, link research up with enterprises, banks, governments and individuals in a seamless manner, whilst still always allowing divergence of opinion and subjectivity to remain, and without the very real danger of polical/economic control that centralised networks present.
The big project is now to re-build all the tools that we have to work with this platform, to create easy user interfaces that need to be aware of the subjectivity of information, so as to allow anybody to always ask about any piece of information: where did this come from? Who said it? What was it the logical consequence of? It should be possible to take different points of views on data: skeptical, trusting, etc… to see what kinds of possibilities are entailed by it.
At present we are busy building a platform for co-operating systems using all the above mentioned standards and tools. The platform is open allowing students, researchers or anyone else to join us on the read-write-web project. We are already working with non-profit organisations such as the French Virtual Assembly that are connecting a number of non profit actors in a network based on a concept they call ‘pair to pair’ where pair stands for project actor idea resource.
Thank you Henry for taking your time to talk with me. Thank you for the Interview!
For more information check out a web site of Henry Story, his Academia.edu page, and you can follow his Twitter feed – Bblfish.
Image sources:
discussing how to create a wish list to our #RDF linked profiles #OSLabs14 #OSFest14 pic.twitter.com/JDFU4i6J32
— Joachim Lohkamp (@JockelLohkamp) May 3, 2014
http://www.w3.org/2005/Incubator/webid/spec/identity/